0. 写在前面
之前搞过语音识别,关键词检索,声纹识别,就是语音合成没有尝试过,所以最近有个项目机会,来调研下看看
1. 背景
2019年百度AI开发者大会上,百度智能云和浦发银行展示了联合创造的国内首个“金融数字人”, 其有颜值、有情感,还懂专业银行知识,将成为国内首个银行“虚拟员工”,开启金融服务新模式。Robin在现场还与数字人“小浦”进行了多轮有趣的互动对话

在实际的业务应用中,会遇到很多挑战性的问题,比如关键字语音识别的准确率,自然语言理解的精确度,语音合成的真实度,面部表情,肢体动作的协调性,嘴唇动作与语音是否一致等等
前几天数字人团队找到我们语音团队,协助支持一个场景的需求,如数字人在回答用户问题的时候,会遇到解决不了的问题,那么就会转向人工服务,这样前后的TTS的风格就不一致了,于是希望我们能够提供些帮助或指导性的建议。
因此我们调研了目前TTS方面的一些框架与方案,记录在此,方便后续的查阅
2. 相关术语
- 韵律学 Prosody: https://en.wikipedia.org/wiki/Prosody_(linguistics)
- 音素 Phonemes: units of sounds, we pronounce as we speak. Necessary since very similar words in the letter might be pronounced very differently (e.g. “Rough” “Though”)
- 声码器 Vocoder: part of the system decoding from features to audio signals. Wave is used in Deep Voice at that stage.
- 基音频率 Fundamental Frequency - F0: lowest frequency of a periodic waveform describing the pitch of the sound.
- 自回归模型 Autoregressive Model: Specifies a model depending linearly on its own outputs and on a parameter set which can be approximated.
- 注意力模型涉及的概念 Query, Key, Value: Key is used by the attention module to compute attention weights. Value is the vector stipulated by the attention weights to compute the module output. A query vector is the hidden state of the decoder.
- 字符集 Grapheme: Cool way to say character. 错误模型 Error Modes: Sub-optimal status for the attention block where it is not able to escape.
- 单音调注意力机制 Monotonic Attention: Use only a limited scope of nodes close in time to the output step. It improves performance for TTS since there is a certain relation btw the output at time t and the input at time t. However, it is not that reasonable for translation problem since words orders might not be the same. https://arxiv.org/pdf/1704.00784.pdf
- MOS: Mean Opinion Score. Crowd-source the evaluation process with native speakers. It is not easy to measure, especially for a layman.
- 上下文向量 Context vector: Output of an attention module which summarizes multiple time-step outputs of the encoder.
- 汉宁窗 Hann Window Function: https://en.wikipedia.org/wiki/Window_function#Hann_window
- Teacher Forcing: Providing model’s expected output at time t as input at time t+1. It is controlled ground-truth feedback as a teacher does to a student.
- Casual convolution: Convolution which does not foresee the future units given the reference time step T which we like to predict next. In practice, it is implemented by setting right padding orientation to normal convolution layers.
3. 典型框架
Deep Voice (25 Feb 2017)
- Text to phonemes. Deterministically computed with a dictionary. Or Seq2Seq model to deal with the unseen words.
- http://www.speech.cs.cmu.edu/cgi-bin/cmudict CMU dictionary
- The same phoneme might hold different durations in different words. We need to predict the duration. It is sequence depended.
- Fundamental frequency for the pitch of each phoneme. It is sequence depended.
- Frequency + Phonemes + Duration = Voice synthesis. It is done via Google’s WaveNet.
- Models
- Segmentation Model
- Segment audio signal to phonemes.
- CTC loss
- Predict phoneme pairs due to probability mass
- Inputs:
- Audio clip of “It was early spring”
- Phonemes (label)
- [IH1, T, ., W, AA1, Z, ., ER1, L, IY0, ., S, P, R, IH1, NG, .]
- Outputs:
- Pairs of Phonemes with their start time
- [(IH1, T, 0:00), (T, ., 0:01), (., W, 0:02), (W, AA1, 0:025), (NG, ., 0:035)]
- Pairs of Phonemes with their start time
- Fundamental Freq & Duration Models
-
Segmentation model predictions are the labels for these models.
- Inputs:
- Phonemes
- Outputs:
- Duration, Probability, F0 for each phoneme; [H, 0.1, 25hz], …
-
- Segmentation Model
- Audio Synthesizer Model
- Simplified WaveNet
- Inputs:
- Duration and F0 for phonemes + audio signals (labels)
- Outputs:
- Synthesis audio signal
Deep Voice 2 (24 May 2017)
- Using WaveNet as vocoder (synthesis from features to audio signal)
- Experiments with Tacotron using WaveNet
- Speaker embedding
- Provide speaker embedding as;
- initial hidden state for RNNs
- concatenate the embedding with input features for every RNN steps.
- multiply layer activation with the embedding
- Text => Phoneme Dictionary => Phonemes => S+Durations => Upsampling => S+ Frequency => S+Vocal => Speech
- Segmentation Model
- Finding phoneme boundaries
- Predict phoneme pairs as a seq2seq problem
- Deep Voice 1 model + BN + residual connections
- Duration Model
- Labels are discretized buckets of log-scale duration.
- CRF is used to employ the dependence btw phonemes while predicting the sequence duration.
- Frequency Model
- Use Praat software to extract the fundamental frequency
- Input: upsampled features by the duration predicted by the duration model.
- Output: normalized f => F0 computed by speaker specific mean and std.
- Synthesis Model
- Inputs: F0 and phonemes computed by Duration and Frequency models.
- Output: Synthesis speeches
- Differences from Deep Voice 1:
- Speaker embedding
- Separation of duration and frequency models
Deep Voice 3 (20 Oct 2017)
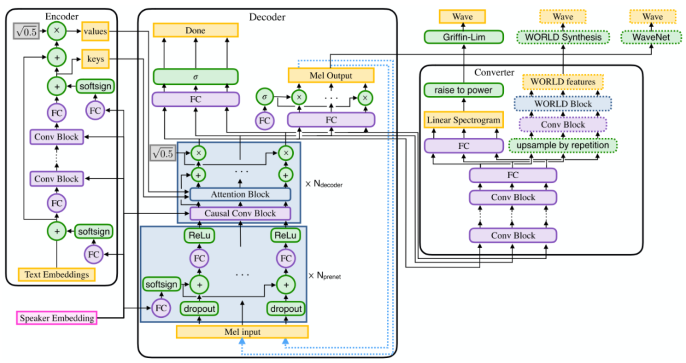
- Fully convolutional
- Text -> Mel-band spectrogram -> Audio
- WaveNet > WORLD > Griffin-Lim by the measure of MOS
- WaveNet 3x, WORLD 40X real-time in CPU
- Results are comparable to Tacotron but DeepVoice 3 faster in training ??
- Monotonic Attention
- Complex text preprocessing - A tools called Gentle used to find pauses btw words.“Either way%you should shoot/very slowly%.” - long pause after ‘way’, short pause after ‘short’
- Joint representation of Chars and Phonemes
- Fixing pronunciation errors by using a Phoneme dict.
- Character embedding
- Phoneme embedding
- Char + Phoneme embedding
- Encode Model
- Given the embedding compute trainable internal representations.
- Input:
- Char, Phoneme or Char + Phoneme embedding vector
- Output:
- Encoded internal representation separated into Key, Value vectors.
- Attention Block
- Monotonic attention
- Query, Key, Value
- Fixed window Softmax
- Positional Encoding (allows attention on a sequence without RNN)
- Decoder Model
- Input:
- Attended feature vector + Previous decoder output
- Output:
- next R audio feature frames
- binary final frame prediction
- Input:
- Converter
- Spectogram to Audio
- Wavenet, WORLD or Griffin-Lim
- Differences from Deep Voice 2
- Fully convolutional
- WORLD vocoder in deployment
- No Separate Duration, Frequency, Segmentation models. End-2-End as it can get :)
- My 2 cents
- At a high-level, Easy and End2End but so many nitty-gritty details under the hood.
- Weight norm for conv layers hidden in Appendix
- Junction of inputs; chars+phonemes
- Speaker embedding - trained how and when?
- Claimed to be fast in training but I don’t think fast in hyper-tunning and experimenting.
- Like that part
- “Running inference with a TensorFlow graph turns out to be prohibitively expensive, averaging approximately 1 QPS 9.”
- On average all Deep Voice implementation might be hard for small teams since each paper has at least 8 people devoting fully day time on it.
- It is also a strange path that they first separate duration and frequency model on Deep Voice 2 then they completely resolve it into the whole end2end architecture. Probably Tacotron influence.
Tacotron (6 April 2017)
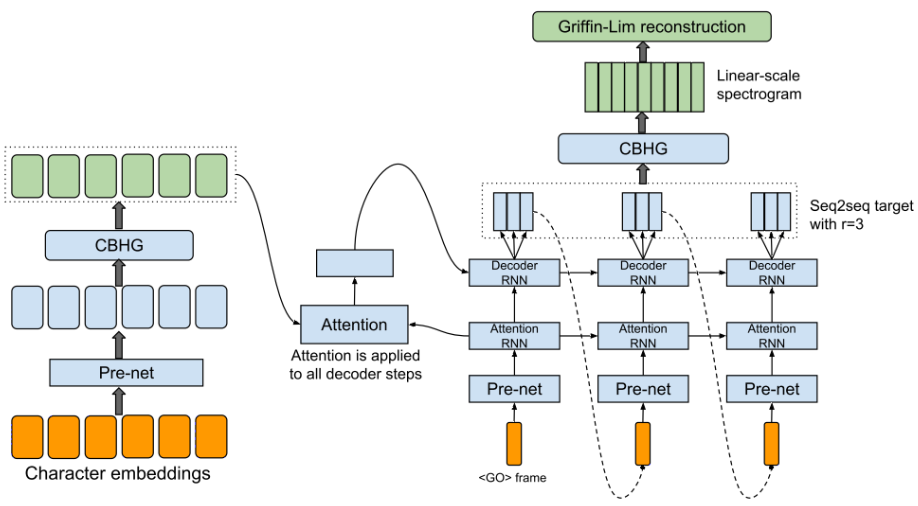
- End2End
- Faster than WaveNet
- Character sequence => Audio Spectrogram => Synthesized Audio
- Example Results: https://google.github.io/tacotron/publications/tacotron/index.html
- Decoder predicts r frames - one at a time
- Faster training
- Faster convergence
- Decoder is autoregressive
- Training with every r-th ground truth frame of time t-1.
- Inference by providing the r-th prediction at time t-1 for the time step t
- Griffin-Lim synthesizer
- Pre-Net
- Encoder Model
- CBHG module
- input: Embedding vector
- output: encoded representation
- Attention Module
- input: encoded representation, decoder query
- output: context vector
- Decoder Model
- input: context vector, previous r-th frame output
- output: r spectrogram frames
- Post-Net
- CBHG module
- input: decoded r spectrogram frames
- output: general audio frame can be synthesized to the waveform
- Parameters:
- 50 ms frame length
- 12.5 ms frameshift ?
- 2048 points Fourier Transform
- 24 kHz sampling for all experiments
- Adam optimizer
- r=2 and r=5 also works well
- LR 0.001 -> 0.0005 -> 0.0003 -> 0.0001 after 500K -> 1M -> 2M steps
- L1 loss for decoder and post-processing net with equal weights
- 32 batch size with max-length padded sequences
- My 2 cents:
- Attention module might be changed with Monotonic Attention used in Deep Voice 3
- Griffin-Lim can be switched to - WaveNet for better precision, WORLD for faster results.
- Very straight forward from a high-level to implement
- No support for multi-speaker.
- CBHG is we tried and it worked kind of thing.
- However, Tacotron 2 results are much better regarding the prosody and sound.
Tacotron 2 (16 Dec 2017)
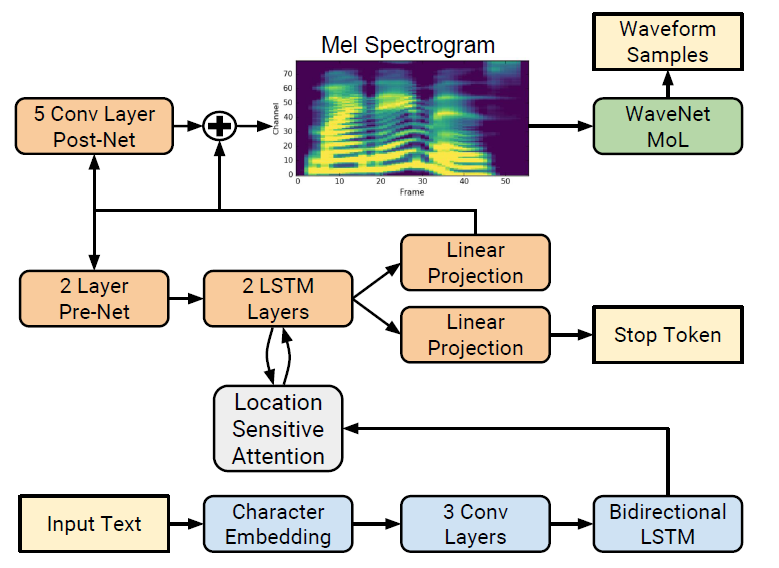
- Examples: https://google.github.io/tacotron/publications/tacotron2/index.html
- WaveNet vocoder
- Text -> Mel-spectrogram -> Audio
- In lie of linguistic features of WaveNet, Tacotron uses intermediate representation used from characters.
- Location sensitive attention
- Parameters:
- 50ms frames, 12,5 ms frameshift, a Hann Window function
- “We transform the STFT magnitude to the mel-scale using an 80 channel mel-filterbank spanning
- 125 Hz to 7.6 kHz, followed by log dynamic range compression”
- Mean Squared Error
- Stop token prediction, concatenation of context vector and the feedback network from the prev. time step is projected to a scalar and passed through a sigmoid function to predict the stop token.
- Mixture of Logistic dist. instead of Softmax predictions.
- 2 stage training; train feature network then WaveNet as the vocoder.
- Teacher forcing is used for models.
- Diff Tacotron 1
- Normal convolution layers over CBHG modules.
- WaveNet vocoder
- Location sensitive attention to achieve a monotonic change of attention weights.
- GRU -> LSTM
- Stop token prediction
- My 2 cents:
- MOS is not a good measure since test time recordings are not meant to be separate from the training set. The exact same sentence or very similar sequences might appear in the Test set. So the success of the model is mostly based on its memorization capabilities of the large dataset.
- No speaker embedding.
- All the dataset is a single person speech recorded by a professional.
- They try to reduce WaveNet computation cost by learning the internal representation by an Encode - Decoder architecture.
- Used character embedding does not say anything about pronunciation. Voice-based embedding might be useful.
Voice Loop (20 July 2017)
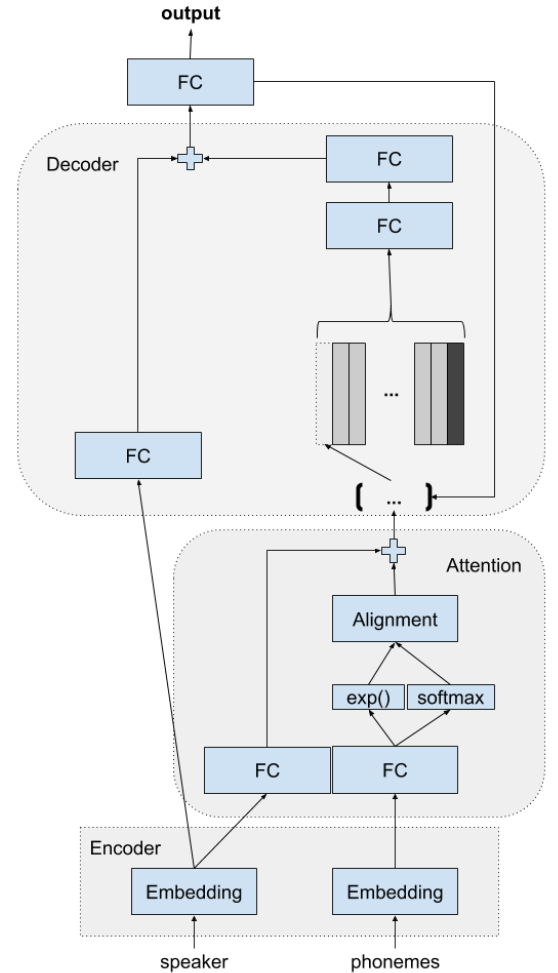
- No need for speech text alignment due to the encoder-decoder architecture.
- No encoding is performed for the input text sequence. At each time step, only the corresponding embedding vector for the given character (phoneme) is used for the upper computations.
- Context computation is done by an attentive memory buffer in lieu of RNN. For each time step, a new vector is added to buffer as the earliest is removed. The buffer keeps the long-term information by using the autoregressive connection to compute the new time step vector.
- Using GMM based attention model (Graved 2013) which ensures monotonic attention.
- Speaker embedding is used for voice adaptation. The embedding is done by a multi-class network trained on speaker identification.
- All networks in the architecture are fully-connected.
- WORLD vocoder is in use for audio synthesis.
- The auto-regressive connection is exploited with teacher-forcing which introduces a combination of the real ground-truth and the previous time-step network output. They discuss using the ground-truth forcing network to predict the next time step only.
- My 2 cents:
- Memory buffer is a cool idea but I am not sure how to employ at cool-start.
- Performing no encoding on text sequence seems out of the way when the input is a list of characters instead of phonemes (they used phonemes).
4. 开源数据集
- VCTK from CSTR
- 109 speakers
- ~44 hours
- 48 kHZ sampling
- http://homepages.inf.ed.ac.uk/jyamagis/page3/page58/page58.html
- LibriSpeech
- http://www.openslr.org/12/
- 1000 hours
- Clean and Noisy sets
- 2484 speakers
- LJ Speech Dataset from Keith Ito
- https://keithito.com/LJ-Speech-Dataset/
- 1 speaker
- ~24 hours
- ~13000 utterencess
- Blizzard Challenge 2012
- Toshiba Research Europe Ltd, Cambridge Research Laboratory
5. 实验
模型
Tacotron 2
数据集
LJ Speech Dataset from Keith Ito
开源框架
https://github.com/mozilla/TTS
实验环境
28 线程 198G内存 Tesla P40 * 4 : /home/users/zhaoqingen/TTS,运行示例 python train.py –config_path config.json
实验说明及结果
采用默认配置参数,迭代 1000 epoch,训练测试的中间结果统计如下
训练过程
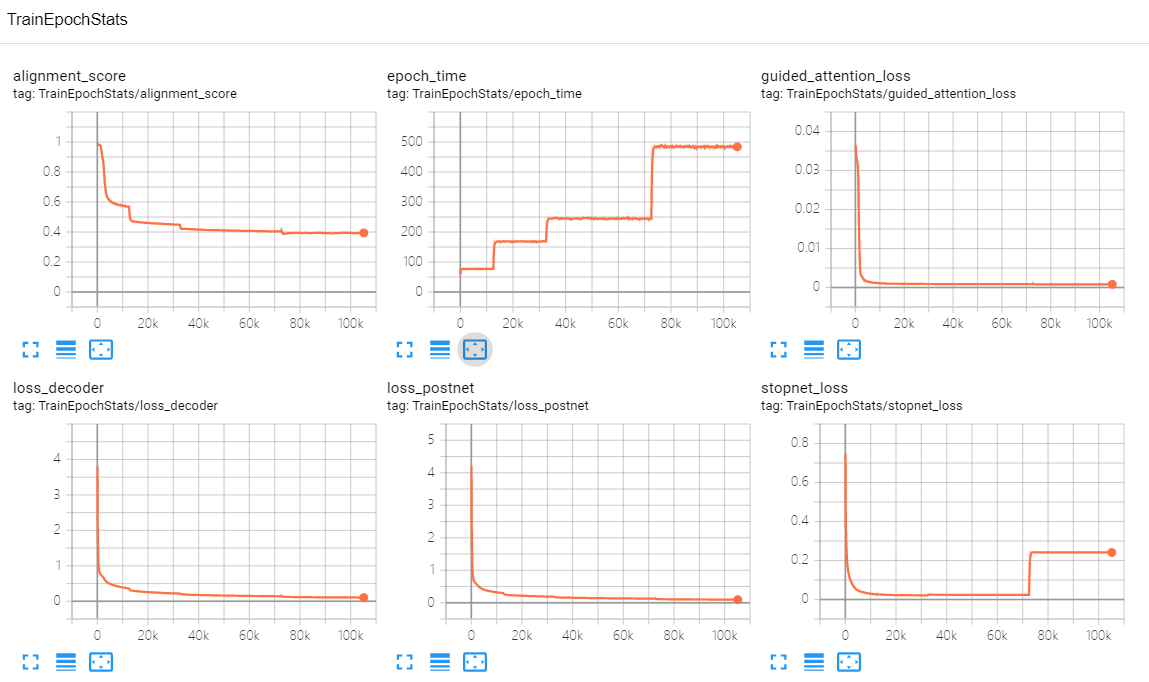
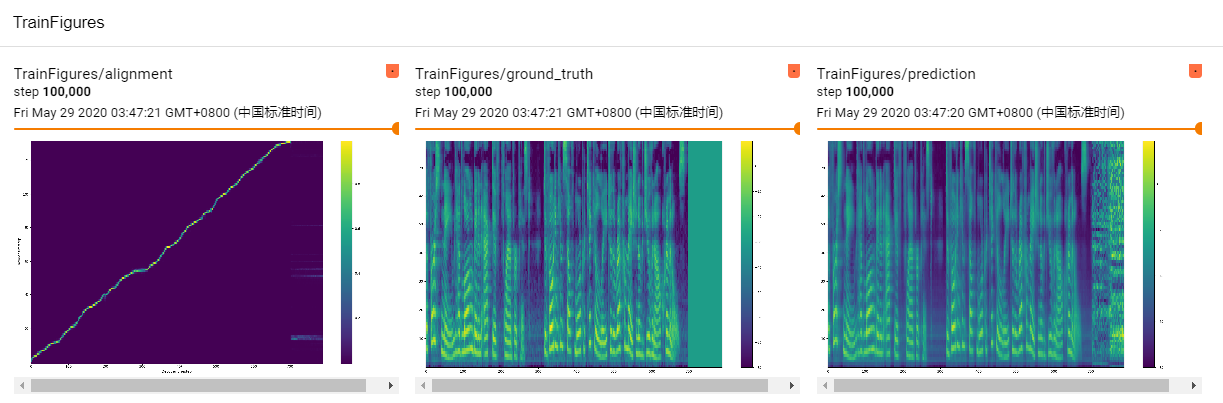
评估过程
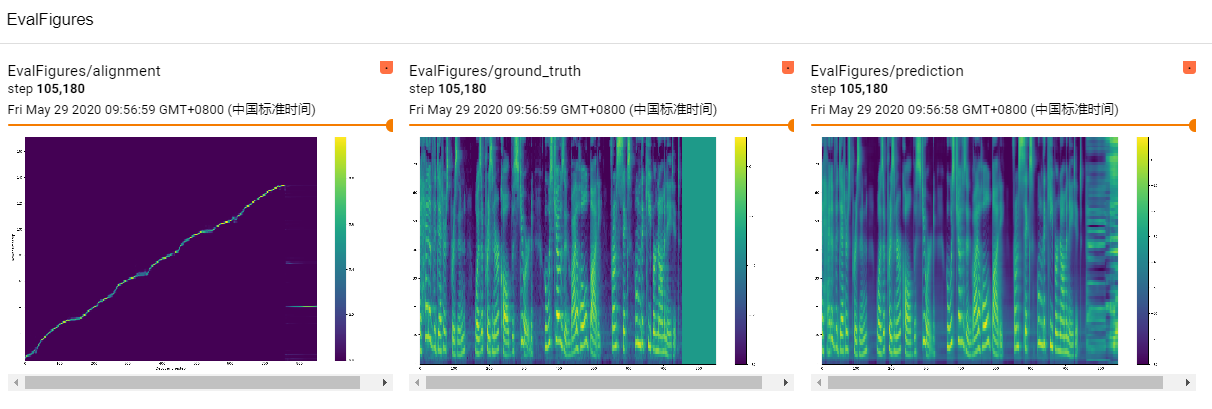

- 更多动态的结果展示,可以参考 tensorboard –logdir %log-path% 命令,log-path 为 训练过程中 tfevents 文件所在的路径,如 events.out.tfevents 文件所在的路径 /home/users/zhaoqingen/Models/LJSpeech/ljspeech-May-25-2020_10+35PM-9d7cb1e
- 更多的Demo,可以参考上述开源框架
实验结论
- 目前合成的音频,主观听起来,能听得懂内容,但是拟人效果还存在差距,目前还在迭代训练中,期待后面训练结束的最终结果
6. 参考文献
- Fitting New Speakers Based on a Short Untranscribed Sample - https://arxiv.org/abs/1710.08969
- Efficiently Trainable Text-to-Speech System Based on Deep Convolutional Networks with Guided Attention - https://arxiv.org/abs/1802.06984
- An Empirical Evaluation of Generic Convolutional and Recurrent Networks for Sequence Modeling - https://arxiv.org/abs/1803.01271
- Towards End-to-End Prosody Transfer for Expressive Speech Synthesis with Tacotron - https://google.github.io/tacotron/publications/end_to_end_prosody_transfer/index.html
- Parallel WaveNet - https://arxiv.org/abs/1711.10433
- Prosody Transfer - https://arxiv.org/pdf/1803.09047.pdf
- Prosody Transfer (Style token) - https://arxiv.org/pdf/1803.09017.pdf
- FFTNet - http://gfx.cs.princeton.edu/pubs/Jin_2018_FAR/fftnet-jin2018.pdf
- TTS-Architectures https://erogol.com/text-speech-deep-learning-architectures/#more-1650

路过的朋友,如果感觉文章对你有启发,能否微信扫一扫,随意打个赏
(如果需要转载,请注明作者和出处 呐喊的少年)
Post Directory
