0. 写在前面
毕业几年一直在语音圈子里面混当,语音识别的引擎框架,从早期 剑桥的HTK,李开复的 Sphinx,到后来的 Povey 的 Kaldi,几乎都摸了一遍,包括语言模型的训练(Ngram,RNNLM),还是声学模型训练(CE,SDT),还是解码器(Viterbi),声纹识别(ivector,xvector),语音唤醒(Key words spotting),给我的感受是,一方面要紧跟公司业务方向大潮流走,毕竟你替公司打工,另外一方面得建立自己一套领域知识与技能体系,最好不要频繁的更换框架,选好了一个就一直走下去,对你的职业成长比较有利
这里我比较推荐 kaldi,不仅仅适合刚入门的新手,也适合职场多年的老鸟

2016年5月15日,阿里集体婚礼
阿里让我成熟了很多,也看清了很多
1. 背景
去年 $Daniel\ Povey$ 提出半正交低秩矩阵分解神经网络($Semi{-}Orthogonal \ Low-Rank\ Matrix\ Factorization\ for\ Deep\ Neural\ Networks$)在语音识别领域获得了 $state \ of \ art$ 的效果,不仅在 $Fisher$ 集合上,同时也在 $Switchboard$ 上得到了验证,所以借鉴并学习下其算法精妙之处,欲用于声纹识别任务上面,实验其效果
2. TDNN-F 介绍
$TDNNs(Time\ Delay\ Neural\ Networks)$是一种时延的神经网络,可以认为是一维的卷积神经网络,在语音识别领域效果表现比较好,而且效率也高。另外近年来减少网络参数的$SVD(Singular\ Value\ Decomposition)$方法也逐渐流行起来,它是将网络权重矩阵因式分解$(Factorize)$成两个更小的矩阵,同时丢弃较小的奇异值。
$Povey $ 将 $SVD$ 应用于 $TDNN$,并加上了一系列策略,如 $ l_2 \ regulation$, $“floating” semi{-}orthogonal \ constraint$, $3{-}stage\ convolution\ per{-}layer$, $dropout$, $skip\ connections$等,整体架构如下:
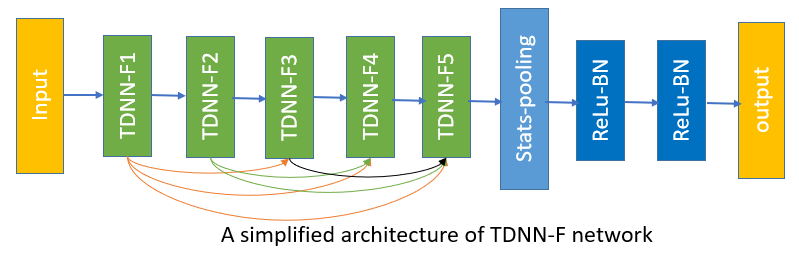
其中 $TDNN{-}F\ Block$ 如下,(为了方便对比,将原始的 $TDNN$ 也贴在下面)
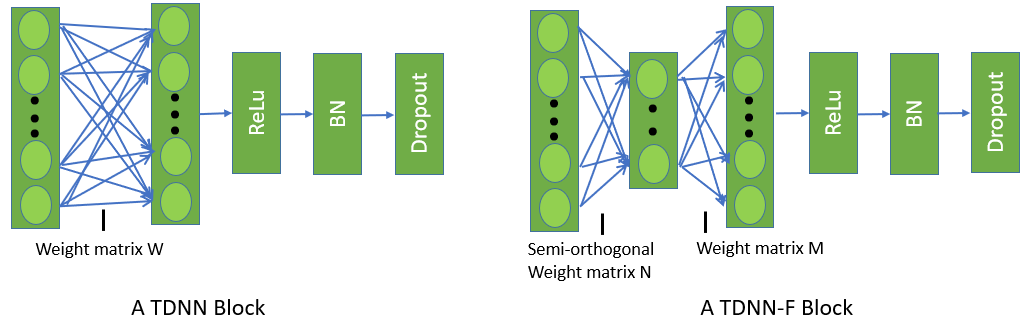
如上图所示,$TDNN{-}F$ 与 $TDNN$ 最大的区别就是将原来的权重矩阵 $M$ 分解为两个矩阵 $A$ 和 $B$,并将 $B$ 约束成半正交的,那么加了半正交约束的 $TDNN-F$ 是如何训练的呢?下面我们结合 $Povey$ 论文和代码着重推导一下这部分(其他DNN常规部分就不在这里推导了)
设 $M$ 为半正交约束的矩阵,即我们期望 $MM^T=I$,半正交矩阵:设$M$的维度为$m\times n$,则 $MM^T=I$ 或 $M^TM=I$,$M$ 即为半正交矩阵
设 $P\equiv MM^T$,因此我们期望 $P=I$,令 $Q=P-I$,则目标函数为 $min \ f=tr(QQ^T)$ 即
\[f=tr(QQ^T)=tr[(P-I)(P^T-I)]\]因此
\[\frac{\partial f}{\partial Q}=2Q\] \[\frac{\partial f}{\partial P}=2P-2I=2Q\] \[\frac{\partial f}{\partial M}=\frac{\partial f}{\partial P}*\frac{\partial f}{\partial M}=4QM\]设学习率为 $\varepsilon$,则$M$的更新方程为 $M\leftarrow M-4\varepsilon QM$ 令 $\varepsilon =\frac{1}{8} $,则:
\[M\leftarrow M-\frac{1}{2} QM\]即
\[M\leftarrow M-\frac{1}{2} (MM^T-I)M\]至此为止,半正交矩阵 $M$ 的更新推导完毕; 但是,我们希望 $M$ 不是一个严格的半正交矩阵,而是一个 $scale$ 的半正交矩阵,因此令 $M=\frac{1}{\alpha}M$,则:
\[\frac{1}{\alpha}M\leftarrow \frac{1}{\alpha}M-\frac{1}{2}(\frac{1}{\alpha^2}MM^T-I)\frac{1}{\alpha}M\] \[M\leftarrow M-\frac{1}{2\alpha^2}(MM^T-\alpha^2I)M\]令 $\beta=\frac{1}{\alpha^2}$
则
\[M\leftarrow M-\frac{1}{2}\beta(P-\alpha^2I)M\]假设 $M$ 的更新公式为$M\leftarrow M+X$ 则:
\[tr(MX^T)=0\] \[X=-\frac{1}{2}\beta(P-\alpha^2I)M\]划简得:
\[tr(M[(P-\alpha^2I)M]^T)=0\] \[tr(MM^T(P-\alpha^2I)^T)=0\] \[tr(P^TP-\alpha^2P)=0\] \[tr(P^TP)=\alpha^2tr(P)\] \[\alpha=\sqrt{tr(P^TP)/tr(P)}\]这样带有 $Scaled$ 的半正交矩阵的更新推导完毕,后续主要是调优,各类优化手段的排列组合尝试了。
3. TDNN-F 拓扑结构
基本的因式分解
在目前流行TDNN框架上,将某一个矩阵或若干个矩阵进行因式分解。例如一个TDNN 的 hidden 层维度为512,那么一个参数矩阵维度为 (512*3)*512,这里3是由于帧的上下文堆叠(splicing)构造而成;现在我们将1536*512的矩阵分解成2个小矩阵,如 $M=AB$,A的维度为1536*128,B的维度是128*512,并且限制B为半正交,这里的128是经验值,通常取较小值,类似 bottleneck。这里可以认为是一个1-d CNN 层带有3*1的 kernel 以及 512个 filter。这里和普通的TDNN比较可以参考上面的框架图。
常用优化方法
维度的各种尝试
实际中,我们在SRE05 SRE06 SRE08做为训练集,SRE04 以及我们的业务数据作为测试集,进行调优。为了方便与原始的TDNN对比,我们一层一层替换原先的网络,并且保持维度一样的情况,然后再加深网络层数(7->14),最后增加隐含层的维度(512->1536),以及bottleneck的维度(128->256)
Droupout
这里我们展现一种比较特殊形式的 dropout,它能带来0.2%~0.3%的绝对提升。它是一种连续的形式,不是0与1,设 $\alpha$是dropout中的超参数,那么我们在训练的时候随机的选择服从均匀分布的$[1-2\alpha,1+2\alpha]$的某个值进行drop,目前超参数的选择机制是开始训练时设置为0,训练到一半的时候设为0.5,最后设置为0,并且注意的是drop的时候是跨越frame的,如前面的3*1,这里的3用drop的准则保持一致
分解层的选择
我们实验发现,在1*1的TDNN层后接3*1的TDNN层,效果没有2*1后接2*1好,这里的参数矩阵采用的半正交约束的,另外也发现了对最后一层的参数矩阵进行半正交约束的效果要比第一层好,并且这里的bottlenec 维度是256
Skip connections
我们从“dense LSTM”受到启发,采用跳转连接,即第M层的输入,不仅仅来源于(M-1)层的输出,而且还来源于(M-2,M-3…)层的输出,而且需要注意的是,由于存在bottleneck,所以这个输出也可以选择来自该层的,即存在不同维度之间的连接选择,例如small->small,small->large,large->large,large->small,4种选择,以及不同的组合。在实际的实验中,发现 small->large这样的连接对效果有提升,一般有0.2%的绝对提升。这里和resnet也有异曲同工之妙,所以也称为resnet-style。
4. 实验说明
我们采用开源的语音识别框架kaldi,进行声纹识别实验,以SRE16的egs为基础,进行TDNNF的尝试。特征输入是23维的MFCC,并进行CMVN规整,同时加上能量的VAD,通过TDNNF网络,输出节点个数 9xxx,表示训练集共有的人数,准则是CE。基本的网络框架大致如下:
# The frame-level layers
input dim=${feat_dim} name=input
relu-batchnorm-layer name=tdnn1 input=Append(-2,-1,0,1,2) dim=512
relu-batchnorm-layer name=tdnn2 input=Append(-2,0,2) dim=512
relu-batchnorm-layer name=tdnn3 input=Append(-3,0,3) dim=512
relu-batchnorm-layer name=tdnn4 dim=512
relu-batchnorm-layer name=tdnn5 dim=1500
# The stats pooling layer. Layers after this are segment-level.
# In the config below, the first and last argument (0, and ${max_chunk_size})
# means that we pool over an input segment starting at frame 0
# and ending at frame ${max_chunk_size} or earlier. The other arguments (1:1)
# mean that no subsampling is performed.
stats-layer name=stats config=mean+stddev(0:1:1:${max_chunk_size})
# This is where we usually extract the embedding (aka xvector) from.
relu-batchnorm-layer name=tdnn6 dim=512 input=stats
# This is where another layer the embedding could be extracted
# from, but usually the previous one works better.
relu-batchnorm-layer name=tdnn7 dim=512
output-layer name=output include-log-softmax=true dim=${num_targets}
5. 数据说明
训练数据 SRE05 SRE06 SRE08 如下(随机挑选了一些):
| data | utt | spk | female |
|---|---|---|---|
| sre05 | 2764 | 719 | 519 |
| sre06 | 18320 | 2227 | 1683 |
| sre08 | 23635 | 7871 | 4946 |
注册与测试数据如下(我们的业务数据,home_made):
| data | utt | spk | female |
|---|---|---|---|
| home_made_enroll | 5890 | 1001 | - |
| home_made_test | 851 | 851 | - |
| data | utt | spk | female |
|---|---|---|---|
| sre04_enroll | 3418 | 307 | 184 |
| sre04_test | 1073 | 306 | 184 |
6. 实验结果
| Model | Size | home_made/EER | sre04/EER | RTF |
|---|---|---|---|---|
| TDNN | 27M | 6.991% | 4.254% | 0.0129 |
| TDNNF | 25M | 6.161% | 4.426% | 0.0114 |
附:TDNNF在语音识别领域的效果如下:
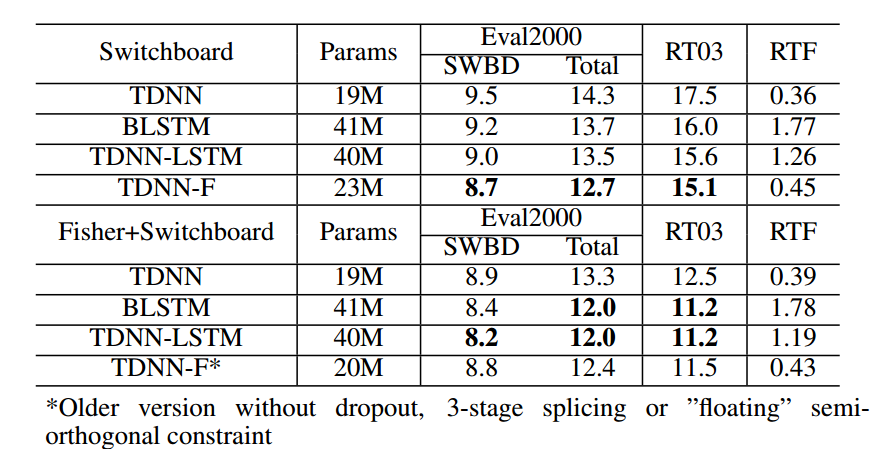
7. 实验结论
将半正交约束的矩阵乘积应用于TDNN,同时采用了其他的几种优化方式,比如skip connections,dropout等,不仅在语音识别任务上取得了效果提升,同时在声纹识别上也取得了小幅度的提升,而且速度更快了,模型更小了。
8. 参考文献
[1] Daniel Povey, Gaofeng Cheng, Yiming Wang, Ke Li, Hainan Xu, Mahsa Yarmohamadi, and Sanjeev Khudanpur, “Semi-orthogonal low-rank matrix factorization for deep neural networks,” in Proceedings of INTERSPEECH, 2018.
[2] R. Prabhavalkar, O. Alsharif, A. Bruguier, and I. McGraw, “On the compression of recurrent neural networks with an application to LVCSR acoustic modeling for embedded speech recognition,” CoRR, vol. abs/1603.08042, 2016.
[3] J. Xue, J. Li, and Y. Gong, “Restructuring of deep neural network acoustic models with singular value decomposition.” in Interspeech, 2013, pp. 2365–2369.
[4] K. J. Han, S. Hahm, B.-H. Kim, J. Kim, and I. Lane, “Deep learning-based telephony speech recognition in the wild,” in Proc. Interspeech, 2017, pp. 1323–1327.

路过的朋友,如果感觉文章对你有启发,能否微信扫一扫,随意打个赏
(如果需要转载,请注明作者和出处 呐喊的少年)
Post Directory
