0. 写在前面
半年前因为项目需要准备搞个小的语音识别框架,但个人几年前HMM-DNN类的搞了不少次了,所以这次不想再搞HMM了,于是乎有了这篇文章。还是惯例,每篇博文都想展示下自己的影子 :)

2018年5月7日,在加拿大卡尔加里,见到了Kaldi的灵魂人物,Povey,于是乎有了合影
1. 背景
自动语音识别$(Speech Recognition)$的目标是把语音转换成文字,因此语音识别系统也叫做$STT(Specch to Text)$系统。语音识别是实现人机自然语言交互非常重要的第一个步骤,把语音转换成文字之后就由自然语言理解系统来进行语义的计算。
一般情况下,语音识别主要有2大类框架,基于$HMM$ 的 $GMM$ 或 $DNN$,与基于$CTC$的 $GMM$ 或 $DNN$,其中基于 $HMM$ 的需要帧级别的对齐结果,而 $CTC$ 则只需要句子级别的标注结果,所耗费的成本更低,并且解码更快,不需要生成 $H$($hmmid$ 与 $transitionid$ 的映射)了,另外 $CTC$ 也广泛图像识别,语义理解等,方法比较新颖,功能也得到广泛验证,所以本文最终选用以 $CTC$ 为准则的 $LSTM$ 网络作为识别方案,下面将详细介绍下
2. LSTM 介绍
LSTM单元
一个典型的 $LSTM(long\ short\ term\ memory)$单元,如下图 所示:
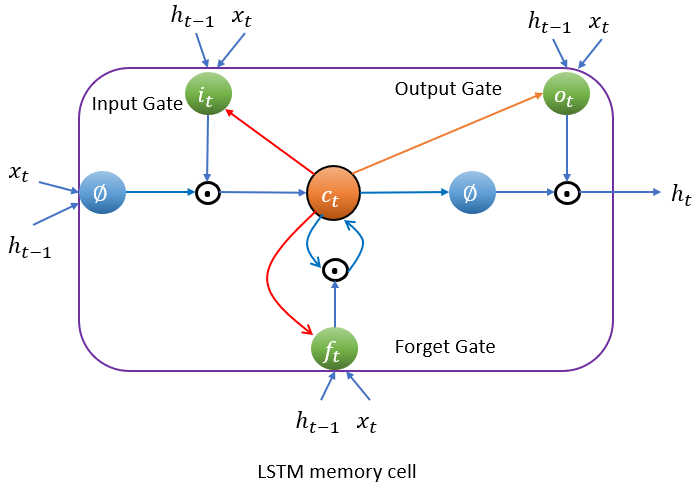
LSTM 结构
我们大致观察到,除了 $x_t$ 外,还包括另外两个向量 $h_t$ $c_t$。可以简单认为$h_t$是短期记忆状态,$c_t$是长期记忆状态。
LSTM 单元的核心思想是其能够学习从长期状态中存储什么,忘记什么,读取什么。长期状态 $c_{t-1}$从左向右在网络中传播,依次经过遗忘门(forget gate)时丢弃一些记忆,之后加法操作增加一些记忆(从输入门中选择一些记忆)。输出$c_{t}$不经任何转换用于下一次的输入门与遗忘门。每个单位时间步长后,都有一些记忆被抛弃,新的记忆被添加进来。另一方面,长时状态经过 $\phi$ 激活函数通过输出门得到短时记忆 $h_t$ ,同时它也是这一时刻的单元输出结果$y_t$ (图中未画出) 。接下来讨论一下新的记忆时如何产生的,门的功能是如何实现的。
首先,当前的输入向量 $x_t$和前一时刻的短时状态 $h_{t-1}$作为输入传给四个全连接层,这四个全连接层有不同的目的:
- 其中主要的全连接层输出 $g_t$(图中最左边部分),它的常规任务就是解析当前的输入 $x_{t}$和前一时刻的短时状态 $h_{t-1}$ 。在基本形式的 RNN 单元中,就与这种形式一样,直接输出了 $h_{t}$ 和 $y_{t}$ 。与之不同的是 LSTM 单元会将一部分$g_t$ 存储在长时状态中。
- 其它三个全连接层被称为门控制器(gate controller)。其采用 Logistic 作为激活函数,输出范围在 0 到 1 之间。正如在结构图中所示,这三个层的输出提供给了逐元素乘法操作,当输入为 0 时门关闭,输出为 1 时门打开。分别为:
- 遗忘门(forget gat)由 $f_t$控制,来决定哪些长期记忆需要被擦除
- 输入门(input gate) 由 $i_t$ 控制,它的作用是处理 $g_t$的哪部分应该被添加到长时状态中,也就是为什么被称为部分存储
- 输出门(output gate)由 $o_t$ 控制,在这一时刻的输出 $h_t$ 和 $y_t$ 就是由输出门控制的,从长时状态中读取的记忆
简要来说,LSTM 单元能够学习到识别重要输入(输入门作用),存储进长时状态,并保存必要的时间(遗忘门功能),并学会提取当前输出所需要的记忆。
这也解释了 LSTM 单元能够在提取长时序列,长文本,录音等数据中的长期模式的惊人成功的原因。
基本形式的 LSTM 单元中,门的控制仅有当前的输入 $x_t$ 和前一时刻的短时状态$h_{t-1}$。不妨让各个控制门窥视一下长时状态,获取一些上下文信息不失为一种尝试。该想法由 F.G.he J.S. 在 2000 年提出。他们提出的 LSTM 的变体拥有叫做窥孔连接的额外连接:把前一时刻的长时状态$c_{t-1}$加入遗忘门和输入门控制的输入,当前时刻的长时状态加入输出门的控制输入,如上图的两条红色连线。
单元的长时状态,短时状态,和单个输入情形时每单位步长的输出的计算总结如下公式所示:
\[\begin{align} &i_t =\varphi(W_ix_t+R_ih_{t-1}+P_ic_{t-1}+b_i) \\ &f_t =\varphi(W_fx_t+R_fh_{t-1}+P_fc_{t-1}+b_f) \\ &c_t=f_t\cdot c_{t-1}+ i_t\cdot \phi(W_cx_t+R_ch_{t-1}+b_c)\\ & o_t=\varphi(W_ox_t+R_oh_{t-1}+P_oc_t+b_o) \\ & h_t=o_t\cdot \phi (c_t) \\ \end{align}\]其中 $x_t$ 是 t 时刻的输入向量,$W$ 是权重矩阵连接输入与LSTM单元,$R$ 是权重方阵连接前一时刻LSTM单元与当前时刻,$P$ 是对角矩阵权重,$b$ 是偏置。$\varphi$ 是$sigmoid$ 激活函数,$\phi$ 是 $tanh$ 激活函数。
双向LSTM单元
将上述单元组织成双向的神经网络层,如下图所示:
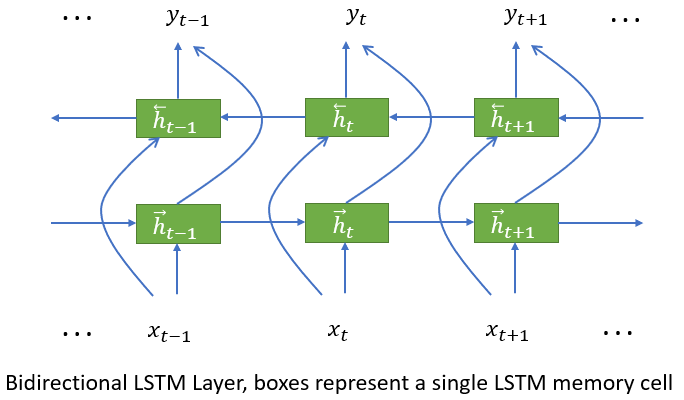
双向LSTM单元
两个方向的数据流是相互独立的,输出是将两个方向的结果拼接起来,然后作为下一层的输入:
\[y_t =[ \overrightarrow h_t , \overleftarrow h_t ]\]3. CTC 介绍
$CTC(Connectionist\ Temporal\ Classification)$ 顾名思义,就是为了短时连接的分类任务而设计的一套准则。它可以使网络在序列的任何位置进行 label 预测,所以就不需要提前切分句子,并且对于输入的对齐也不是那么重要了,它直接输出整个句子的概率和,因此也不需要额外的后处理了
输出与标记的关系
对于一个序列打标签的任务上,我们假设它的 label 的集合是 A,那么扩展的 label 集合是 \(A` = A \cup \{ blank\}\) 其中blank 表示 no label,表示神经网络输出无用或无意义的信息。在给定一个序列 $ x $,长度为 T,在时刻 t,网络输出 $A`$ 中元素 $k$ 的概率记为$y_k^t$,另外我们用${A`}^T$表示长度为$T$的来源于$A`$的序列(网络的输出)的集合。假设 $\pi \in {A^‘}^T$ ,那么给定x,输出$\pi$的概率为:
\[p(\pi |x)=\prod_{t=1}^T y_{\pi_t}^t\]$\pi$ 即网络输出的一条路径,按照一定规则它与一个label 序列 $l$ 相对应,在这个规则下有若干个不同的$\pi$与$l$对应,因此我们定义一个多到一的映射关系:$\mathcal F : {A^`}^T \mapsto A^{\le T}$,我们对输出的路径先去除重复的,然后再去除blanks,例如:
\[\mathcal F (a-ab-) =\mathcal F(-aa--abb)=aab\]因此反过来,计算一个$l$的概率,需要对所有可能产生$l$的路径的概率求和,即:
\[p(l |x)=\sum_{\pi \in \mathcal F^{-1}(l)}p(\pi | x)\]需要注意的是,这里是路径概率的求和,也就是说网络在预测label的时候,不需要提前知道他们在哪里产生的,也就是说允许$CTC$去使用没有经过强对齐的数据。同理 $CTC$ 就不适用于那些需要确定$label$位置的任务,但是实际中,$CTC$输出的$label$的位置很接近原始序列中的位置
blank标记的意义
在原先的$CTC$理论中,是没有$blank$的,所以$\mathcal F(\pi)$仅仅是将重复的labels给去掉。这样会导致2个问题,1)同样的label就不能出现2次了 2)在预测一个label之后需要紧接着预测下一个,这个在实际任务中是一个巨大的负担,因为label与label之间往往会被 unlabeled 数据分割开来,比如在语音识别中,words 之间 会存在短暂的暂停 或 non-speech 的噪音等,因此为了解决上述问题,而引入了 blank
前后向路径概率求和
到目前为止,我们定义了条件概率 $p(l |x)$,即x 对应的可能输出label 序列的概率和。直接计算能产生序列$l$的所有可能路径$\pi$ 几乎是不可能的,计算量随着x的长度 $T$呈指数增长 不过幸运的是,这一类问题,在早期遇到HMM就被解决了,采用了dynamic programming 中的 forward-backward 算法。由于输出的路径上面可能包括 blank,所以我们修改下 label 序列 $l$,在收尾添加 blank,并且在 label 之间也添加 blank,这样构成新的label 序列 $ l` $,如果 $l$的长度是 $U$,那么 $ l` $ 的长度就是$U` =2U+1$,在计算路径概率的时候,我们允许所有的 blank 到 non-blank 的跳转 以及任意两个 non-blank 的跳转,如下图所示:
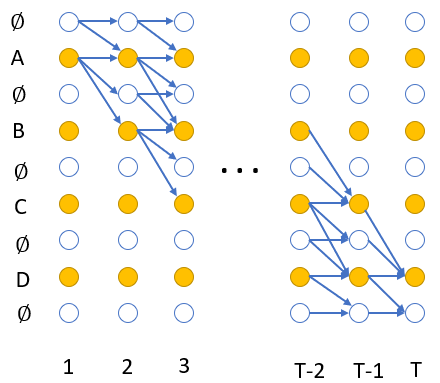
对于某一个label序列 $l$,我们定义前向中的变量 $\alpha (t,u)$,表示所有长度为 t 的路径的概率和,并且路径通过$\mathcal F$ 转换后变成 $l$的前$u/2$部分。另外我们再定义一个路径集合
\[V(t,u)=\{\pi \in A^{`t}:\mathcal F(\pi)=l_{1:u/2},\pi_t=l^`_u\}\]所以
\[\alpha (t,u)=\sum_{\pi \in V(t,u) }\prod_{i=1}^T y_{\pi_i}^i\]因此$l$的概率就可以表达为在时间$T$的时候到达最后的blank与不到达的前向概率之和
\[p(l |x)=\alpha(T,U^`)+\alpha(T,U^`-1)\]所有的路径必须以 blank 开始或者$l$的第一个字符($l_1$),因此需要遵从如下的初始条件:
\[\begin{align} &\alpha(1,1) =y_b^1 \\ &\alpha(1,2) =y_{l_1}^1 \\ &\alpha(1,u) =0,\forall u>2 \\ \end{align}\]因此,我们写成递归形式如下:
\[\alpha (t,u)=y_{l_u^`}^t\sum_{i=f(u)}^u \alpha(t-1,i)\]其中
\[f(u) = \begin{cases} u-1, & \text{if $l_u^`=blank$ or $l_{u-2}^`=l_u^`$} \\ u-2, & \text{otherwise} \end{cases}\]我们定义后向的变量$\beta (t,u)$,从时间t+1开始与前向$\alpha (t,u)$的任意路径共同产生完整的序列$l$的所有路径的概率之和。另外我们定义一个路径集合 \(W(t,u)=\{\pi \in A^{`T-t}:\mathcal F(\pi + \hat \pi)=l,\forall \hat \pi \in V(t,u)\}\)
因此
\[\beta(t,u)=\sum_{\pi \in W(t,u) }\prod_{i=1}^{T-t} y_{\pi_i}^{t+i}\]初始条件如下:
\[\begin{align} &\beta(T,U^`) =\beta(T,U^`-1)=1 \\ &\beta(T,u) =0, \forall u<U^`-1\\ \end{align}\]因此,我们写成递归形式如下:
\[\beta(t,u) =\sum_{i=u}^{g(u)}\beta(t+1,i)y_{l_i^1}^{t+1}\]其中
\[g(u) = \begin{cases} u+1, & \text{if $l_u^`=blank$ or $l_{u+2}^`=l_u^`$} \\ u+2, & \text{otherwise} \end{cases}\]损失函数与梯度
我们定义训练集为$S$,输入与目标的对是$(x,z)$,因此我们定义损失函数为
\[\mathcal L(S)=-ln\prod_{(x,z)\in S}p(z|x)=-\sum_{(x,z)\in S}ln\ p(z|x)\]我们设定 \(X(t,u)=\{\pi \in A^{`T}:\mathcal F(\pi)=z,\pi_t=z^`_u\}\) 因此
\[\alpha(t,u)\beta(t,u)=\sum_{\pi\in X(t,u)}\prod_{t=1}^Ty_{\pi_t}^t=\sum_{\pi\in X(t,u)}p(\pi|x)\]对于任意t,我们要对所有的u的求和,得到
\[p(z|x)=\sum_{u=1}^{z^`}\alpha(t,u)\beta(t,u)\]因此
\[\mathcal L(x,z)=-ln \sum_{u=1}^{z^`}\alpha(t,u)\beta(t,u)\]我们首先对网络的输出 $y_k^t$求偏导得:
\[\frac{\partial \mathcal L(x,z)}{\partial y_k^t}=-\frac{\partial ln p(z|x)}{\partial y_k^t}=-\frac{1}{p(z|x)}\frac{\partial p(z|x)}{\partial y_k^t}\]由于网络输出是相互独立的,所以我们只需要考虑在时刻t通过label k的路径即可,其他路径不需要考虑,即
\[\frac{\partial \alpha(t,u)\beta(t,u)}{\partial y_k^t} = \begin{cases} \frac{ \alpha(t,u)\beta(t,u)}{ y_k^t}, & \text{if $k$ occurs in $z^`$} \\ 0, & \text{otherwise} \end{cases}\]另外我们定义位置u的集合
\[B(z,k)=\{u:z_u^`=k\}\]得到:
\[\frac {\partial p(z|x)}{\partial y_k^t}=\frac{1}{y_k^t}\sum_{u\in B(z,k)}\alpha(t,u)\beta(t,u)\]因此化简为:
\[\frac {\partial \mathcal L(x,z)}{\partial y_k^t}=\frac{1}{p(z|x)y_k^t}\sum_{u\in B(z,k)}\alpha(t,u)\beta(t,u)\]然后对softmax层的输入$\alpha_k^t$求偏导得
\[\frac {\partial \mathcal L(x,z)}{\partial \alpha_k^t}=-\sum_{k^`}\frac{\partial \mathcal L(x,z)}{\partial y_k^t}\frac{\partial y_k^t}{\partial \alpha_k^t}\]其中 $k`$ 表示所有输出单元的集合。 由于:
\[\begin{align} y_k^t & =\frac{e^{\alpha_k^t}}{\sum_{k^`}e^{\alpha_k^t}} \\ \Rightarrow\frac{\partial y_k^t}{\partial \alpha_k^t}&=y_{k^`}^t δ_{kk^`}-y_{k^`}^ty_{k}^t\\ \end{align}\]所以最终划简为:
\[\frac {\partial \mathcal L(x,z)}{\partial \alpha_k^t}=y_{k}^t-\frac{1}{p(z|x)}\sum_{u\in B(z,k)}\alpha(t,u)\beta(t,u)\]至此梯度信息传递已经推导完毕,其他可以通过微分链式法则进行同理推导
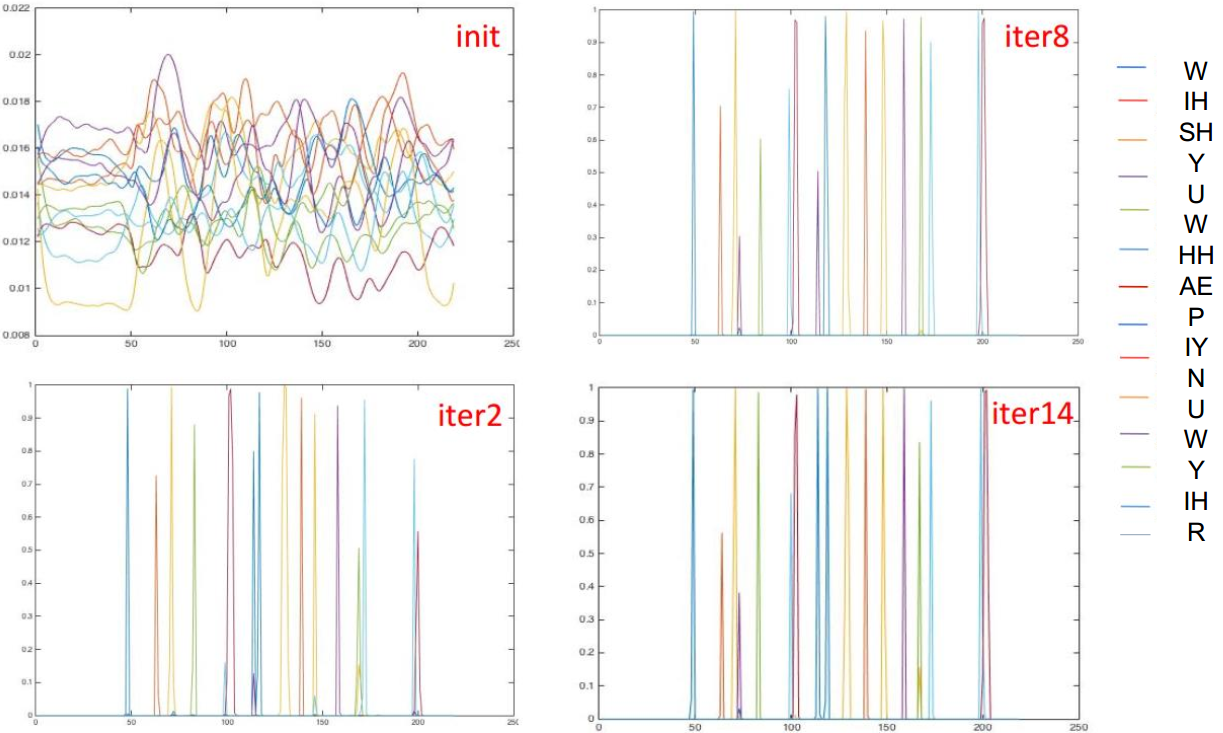
附:一个内容为“Wish You Happy New Year”,音素为“W IH SH Y UW HH AE P IY N UW Y IH R”的音频在训练过程中网络的输出概率示意图:
4. 基于WFST的解码
CTC的解码不同于HMM,前者只需要3部分融合即可,即 TLG,G 网络是由 Ngram 的 ARPA文件生成,可以简单认为是一个词到词的网络,如下图所示:
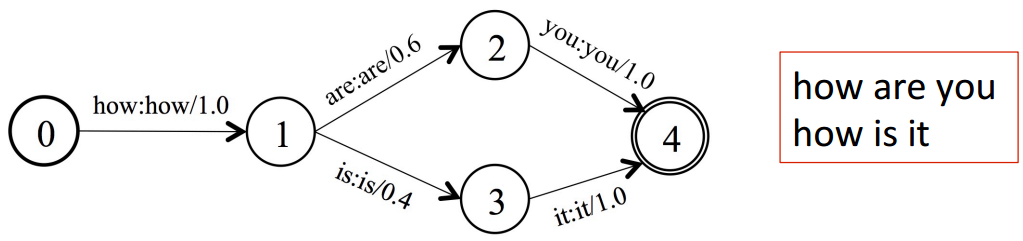
L 即词典网络,可以简单认为是一个发音到词的网络,如下图所示:
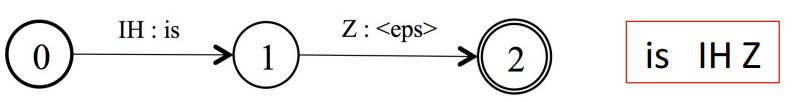
这里需要注意一下,建模单元设定的问题,如果是针对phone建模,那么是上面形式的网络,如果是针对字母建模,那么网络如下图所示:
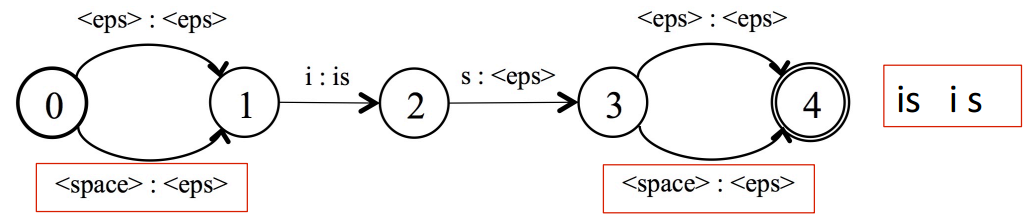
最后一个网络 T,可以认为是CTC中的路径到建模单元的映射,如下图所示:
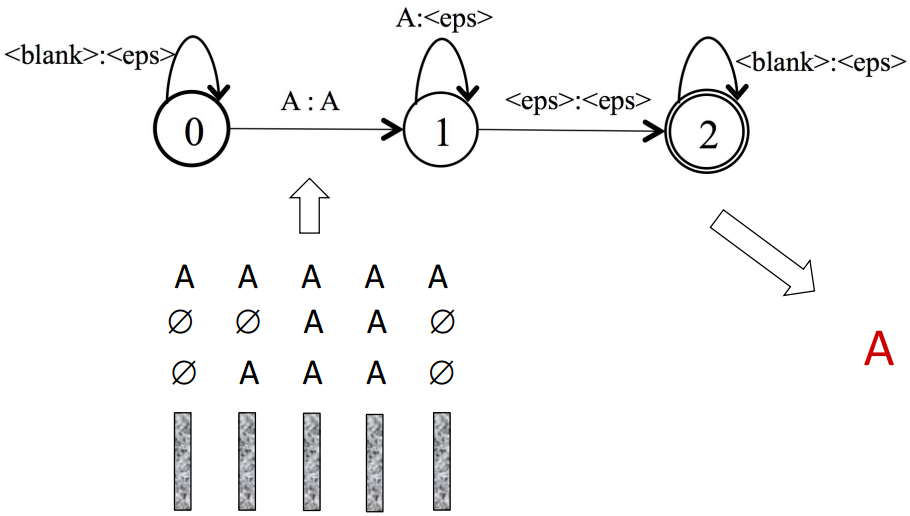
将3个网络融合起来形成解码搜索的大网络 $S=T\circ min(det(L \circ G))$,在该网络上进行 Token-passing 的 beam-search 解码
5. 实验说明
我们在开源的语音识别框架 eesen 基础上,进行数字串识别实验。特征输入是40维的MFCC,并进行全句CMVN规整,通过4层BLSTM网络,上下4帧拼接,总的输入维度360,LSTM-Cell 维度为640,两个方向各自320,输出维度是23,其中 phone 22个 外加一个 blank,采用SGD更新网络权重。
6. 实验过程
数据准备(音频数据,词典,语言模型)
echo =====================================================================
echo " Data Preparation "
echo =====================================================================
# download the 100hr training data and test sets.
for part in dev-clean test-clean dev-other test-other train-clean-100; do
local/download_and_untar.sh $data $data_url $part || exit 1;
done
# download the LM resources
local/download_lm.sh $lm_url $lm_data || exit 1;
# format the data as Kaldi data directories
for part in dev-clean test-clean dev-other test-other train-clean-100; do
# use underscore-separated names in data directories.
local/data_prep.sh $data/LibriSpeech/$part $exp_base/$(echo $part | sed s/-/_/g) || exit 1;
done
英文词典
A AH
A''S EY Z
A'BODY EY B AA D IY
A'COURT EY K AO R T
A'D EY D
A'GHA EY G AH
A'GOIN EY G OY N
A'LL EY L
A'M EY M
A'MIGHTY EY M AY T IY
......
ZYL Z IH L
ZYL'S Z IH L Z
ZYMOTIC Z AY M AA T IH K
ZYNDRAM Z IH N D R AE M
ZYNOOL Z IH N UW L
ZYNOOL'S Z IH N UW L Z
ZYOBOR Z AY OW B AO R
ZZ Z
ZZZ Z Z
ZZZZ Z AH Z
特征提取
echo =====================================================================
echo " FBank Feature Generation "
echo =====================================================================
# Split the whole training data into training (95%) and cross-validation (5%) sets
# utils/subset_data_dir_tr_cv.sh --cv-spk-percent 5 data/train_si284 data/train_tr95 data/train_cv05 || exit 1
utils/subset_data_dir_tr_cv.sh --cv-spk-percent 5 $exp_base/train_clean_100 $exp_base/train_tr95 $exp_base/train_cv05 || exit 1
# Generate the fbank features; by default 40-dimensional fbanks on each frame
fbankdir=fbank
# Only apply different transforms to train
set=train_tr95
for vtlnw in 0.8 1.0 1.2; do
for spkrate in 8 10 11; do
steps/make_fbank_mult.sh --vtln true --vtln-warp $vtlnw --tag ${spkrate}_$vtlnw \
--cmd "$train_cmd" --nj 14 --fbank-config ${fb_conf}-${spkrate} $exp_base/$set $exp_base/make_fbank/$set $exp_base/$fbankdir || exit 1;
done
done
utils/fix_data_dir.sh $exp_base/$set || exit;
steps/compute_cmvn_stats_mult.sh --tag 10_1.0 $exp_base/$set $exp_base/make_fbank/$set $exp_base/$fbankdir || exit 1;
# Use standard feature extraction for test sets.
# A simple extension would be to apply the different transforms to test and combine with ROVER.
# this should provide an improvement albeit with need for multiple decodings.
set=train_cv05
steps/make_fbank.sh --cmd "$train_cmd" --nj 14 --fbank-config ${fb_conf}-10 $exp_base/$set $exp_base/make_fbank/$set $exp_base/$fbankdir || exit 1;
utils/fix_data_dir.sh $exp_base/$set || exit;
steps/compute_cmvn_stats.sh $exp_base/$set $exp_base/make_fbank/$set $exp_base/$fbankdir || exit 1;
for set in dev_clean test_clean dev_other test_other ; do
steps/make_fbank.sh --cmd "$train_cmd" --nj 14 --fbank-config ${fb_conf}-10 $exp_base/$set $exp_base/make_fbank/$set $exp_base/$fbankdir || exit 1;
utils/fix_data_dir.sh $exp_base/$set || exit;
steps/compute_cmvn_stats.sh $exp_base/$set $exp_base/make_fbank/$set $exp_base/$fbankdir || exit 1;
done
网络拓扑结构
<Nnet>
<BiLstmParallel> <InputDim> 360 <CellDim> 640 <ParamRange> 0.1 <LearnRateCoef> 1.0 <MaxGrad> 50.0 <FgateBias> 1.0 <ForwardDropoutFactor> 0.2 <ForwardSequenceDropout> T <RecurrentDropoutFactor> 0.2 <RecurrentSequenceDropout> T <NoMemLossDropout> T <TwiddleForward> T
<BiLstmParallel> <InputDim> 640 <CellDim> 640 <ParamRange> 0.1 <LearnRateCoef> 1.0 <MaxGrad> 50.0 <FgateBias> 1.0 <ForwardDropoutFactor> 0.2 <ForwardSequenceDropout> T <RecurrentDropoutFactor> 0.2 <RecurrentSequenceDropout> T <NoMemLossDropout> T <TwiddleForward> T
<BiLstmParallel> <InputDim> 640 <CellDim> 640 <ParamRange> 0.1 <LearnRateCoef> 1.0 <MaxGrad> 50.0 <FgateBias> 1.0 <ForwardDropoutFactor> 0.2 <ForwardSequenceDropout> T <RecurrentDropoutFactor> 0.2 <RecurrentSequenceDropout> T <NoMemLossDropout> T <TwiddleForward> T
<BiLstmParallel> <InputDim> 640 <CellDim> 640 <ParamRange> 0.1 <LearnRateCoef> 1.0 <MaxGrad> 50.0 <FgateBias> 1.0 <ForwardDropoutFactor> 0.2 <ForwardSequenceDropout> T <RecurrentDropoutFactor> 0.2 <RecurrentSequenceDropout> T <NoMemLossDropout> T <TwiddleForward> T
<AffineTransform> <InputDim> 640 <OutputDim> 44 <ParamRange> 0.1
<Softmax> <InputDim> 44 <OutputDim> 44
</Nnet>
训练
echo =====================================================================
echo " Network Training "
echo =====================================================================
# setup directories
mkdir -p $train_dir/nnet
# Copy network topology to nnet.proto
cp config/nnet.proto.$exp $exp_base/
cp config/nnet.proto.$exp $train_dir/nnet.proto
# Label sequences; simply convert words into their label indices
utils/prep_ctc_trans.py $lang_dir/lexicon_numbers.txt \
$exp_base/train_tr95/text "<UNK>" "<SPACE>" | gzip -c - > $train_dir/labels.tr.gz
utils/prep_ctc_trans.py $lang_dir/lexicon_numbers.txt \
$exp_base/train_cv05/text "<UNK>" "<SPACE>" | gzip -c - > $train_dir/labels.cv.gz
# Train the network with CTC. Refer to the script for details about the arguments
steps/train_ctc_parallel_mult.sh --tags "10_1.0 8_1.0 11_1.0 8_0.8 10_1.2 10_1.0 11_0.8 8_1.2 10_0.8 11_1.2" \
--skip true --splice true --splice-opts "--left-context=1 --right-context=1" --skip-frames 3 --skip-offset 1 \
--add-deltas true --num-sequence $train_seq_parallel --halving-after-epoch $half_after_epoch --frame-num-limit $frame_limit \
--feats-tmpdir $feats_tmpdir --max-iters $aug_iter --learn-rate 0.00004 --report-step 1000 --write-final false \
$exp_base/train_tr95 $exp_base/train_cv05 $train_dir || exit 1;
# for halfing just use the regular features 10_1.0
steps/train_ctc_parallel_mult.sh --tags "10_1.0" \
--skip true --splice true --splice-opts "--left-context=1 --right-context=1" --skip-frames 3 --skip-offset 1 \
--add-deltas true --num-sequence $train_seq_parallel --halving-after-epoch $half_after_epoch --frame-num-limit $frame_limit \
--feats-tmpdir $feats_tmpdir --max-iters $max_iter --learn-rate 0.00004 --report-step 1000 \
$exp_base/train_tr95 $exp_base/train_cv05 $train_dir || exit 1;
解码
echo =====================================================================
echo " Decoding "
echo =====================================================================
# Decoding with the librispeech dict
for test in test_clean test_other dev_clean dev_other; do
for lm_suffix in tgsmall tgmed; do
steps/decode_ctc_lat_splicefeat.sh --cmd "$decode_cmd" --nj 10 --beam 17.0 --lattice_beam 8.0 --max-active 5000 --acwt 0.9 \
--skip true --splice true --splice-opts "--left-context=1 --right-context=1" --skip-frames 3 --skip-offset 1 \
${lang_dir}_test_${lm_suffix} $exp_base/$test $train_dir/decode_${test}_${lm_suffix} || exit 1;
done
done
7. 实验结果
## Results for NML-sequence + Forward-sequence stochastic combination with max perturbation
$ for x in exp/nml_seq_fw_seq_tw/train_lstm/*decode_*; do [ -d $x ] && grep WER $x/wer_* |utils/best_wer.sh ;done
# dev_clean
%WER 7.44 [ 4045 / 54402, 490 ins, 383 del, 3172 sub ] exp/nml_seq_fw_seq_tw/train_lstm/decode_dev_clean_tgmed/wer_12_0.5
%WER 7.93 [ 4315 / 54402, 486 ins, 444 del, 3385 sub ] exp/nml_seq_fw_seq_tw/train_lstm/decode_dev_clean_tgsmall/wer_14_1.0
# dev_other
%WER 24.00 [ 12229 / 50948, 1280 ins, 1609 del, 9340 sub ] exp/nml_seq_fw_seq_tw/train_lstm/decode_dev_other_tgmed/wer_10_1.0
%WER 25.05 [ 12762 / 50948, 1345 ins, 1664 del, 9753 sub ] exp/nml_seq_fw_seq_tw/train_lstm/decode_dev_other_tgsmall/wer_9_0.5
# test_clean
%WER 8.15 [ 4286 / 52576, 552 ins, 422 del, 3312 sub ] exp/nml_seq_fw_seq_tw/train_lstm/decode_test_clean_tgmed/wer_11_0.5
%WER 8.67 [ 4557 / 52576, 543 ins, 506 del, 3508 sub ] exp/nml_seq_fw_seq_tw/train_lstm/decode_test_clean_tgsmall/wer_12_1.0
# test_other
%WER 25.08 [ 13130 / 52343, 1319 ins, 1733 del, 10078 sub ] exp/nml_seq_fw_seq_tw/train_lstm/decode_test_other_tgmed/wer_10_1.0
%WER 26.12 [ 13674 / 52343, 1396 ins, 1701 del, 10577 sub ] exp/nml_seq_fw_seq_tw/train_lstm/decode_test_other_tgsmall/wer_10_0.5
8. 实验结论
利用开源框架eesen,可以快速构建一个完整的端到端的语音识别框架,并在数据集上取得一定的识别效果
9. 参考文献
[1] Y. Miao, M. Gowayyed, and F. Metze, “EESEN: End-to-End Speech Recogni0on using Deep RNN Models and WFST-based Decoding,” in Proc. ASRU. IEEE, 2015.
[2] T. N. Sainath, O. Vinyals, A. Senior, H. Sak, “Convolu0onal, long short-term memory, fully connected deep neural networks,” in Proc. ICASSP. IEEE, 2015.
[3] R. Jozefowicz, W. Zaremba, and I. Sutskever, “An empirical explora0on of recurrent network architectures,” in Proc ICML, 2015.
[4] A. Graves and N. Jaitly, “Towards end-to-end speech recogni0on with recurrent neural networks,” in Proc. ICML, 2014.
[5] A. Y. Hannun, A. L. Maas, D. Jurafsky, and A. Y. Ng, “First-pass large vocabulary continuous speech recogni0on using bi-direc0onal recurrent DNNs,” arXiv preprint arXiv:1408.2873, 2014.
[6] Y. Miao and F. Metze, “On speaker adapta0on of long short-term memory recurrent neural networks,” in Proc. INTERSPEECH. ISCA, 2015.
[7] Y. Liu, P. Fung, Y. Yang, C. Cieri, S. Huang, and D. Graff, “HKUST/MTS: a very large scale Mandarin telephone speech corpus,” in Chinese Spoken Language Processing, 2006.
[8] H. Sak, A. Senior, K. Rao, and F. Beaufays, “Fast and accurate recurrent neural network acoustic models for speech recogni0on,” arXiv preprint arXiv:1507.06947, 2015.
[9] N. Dehak, R.Dehak, P. Kenny, N.Brummer, P. Ouellet, and P. Dumouchel, “Support vector machines versus fast scoring in the low-dimensional total variability space for speaker verification,” in Proc. Interspeech, 2009.
[10] Jajadev Billa, “Improving LSTM-CTC based ASR performance in domains with limited training data”, jb1999

路过的朋友,如果感觉文章对你有启发,能否微信扫一扫,随意打个赏
(如果需要转载,请注明作者和出处 呐喊的少年)
Post Directory
